URLNetについてのお話
URL Embeddingについて書かれた論文を紹介します。紹介する論文は
「URLNet: Learning a URL Representation with Deep Learning for Malicious URL Detection」(Hung Le et al., 2018) Link: https://arxiv.org/pdf/1802.03162.pd
URL(文字列表現)を数値ベクトルの形式で表現する手法を紹介しています。
お馴染みのword2vecでのembeddingとは異なる点があります。教師あり学習で、目的にあったembeddingを実現させます。論文で使われている応用例が、不正なサイトに飛ばず悪質なURLかどうかを見分けるためにembeddingが使われています。
問題の設定
与えられているURLが悪質かどうかを分類する、分類器を構築します。教師あり学習なのでデータはURL(feature)とラベル(target)のペアとなり、ラベルが1だと悪質、−1だと悪質でないことになります。$T$個のペアがモデル構築に使用されます
$$\{(u_1, y_1), ..., (u_T, y_T)\}$$
$u_j$がURL、$y_j$がラベルで、$y_j = +1$または$y_j=-1$となります。
モデル全体像
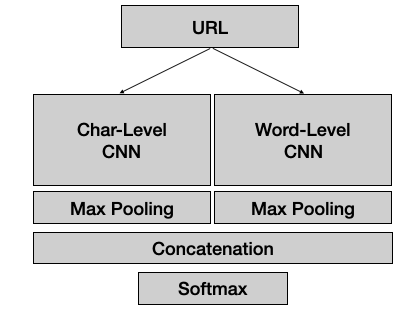
ざっくりになってしまいますが
- URLがインプットされ
- 畳み込み層(CNN)を通り
- Poolingで次元を一次元ベクトルに次元削減
- ベクトルを連結(ここの層から出力されるベクトルがURL Embeddingです)
- 最後にsoftmax層の出力結果が分類に使われる
今回は以下の要点をみていきたいです。
URLをCNNに入れるためは?Char-Level CNNとWord-Level CNNの違いは?
まずはChar-Level CNNからみていきましょう。
Char-Level CNN
URL→toknize→char id→embedding matrix
embedding matrixがCNN層に入ることになります。
URLがhttps://www.hatena.ne.pjだとすると、
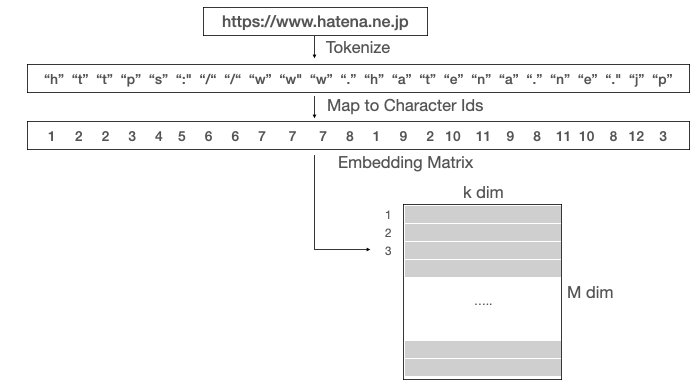
各文字を一意となるIDで表現し、またそのIDが行列(Embedding Matrix)のどの行を使うか指定します。入力されるURLの文字数は自由ですが、内部では必ず200文字になるように設定されます。
200文字未満の場合、補完が行われます。
例えば、www.hatena.ne.jp<PAD><PAD><PAD><PAD>・・・<PAD>
補完専用の文字ID<PAD>を用意して、行列の特定の行を指定するようになります。
200文字を超える場合、200文字以内の文字のみ考慮されます。
Embedding matrixの初期値はランダムに生成されますがbackpropagationにより数値が調整されます。
Word-Level CNN
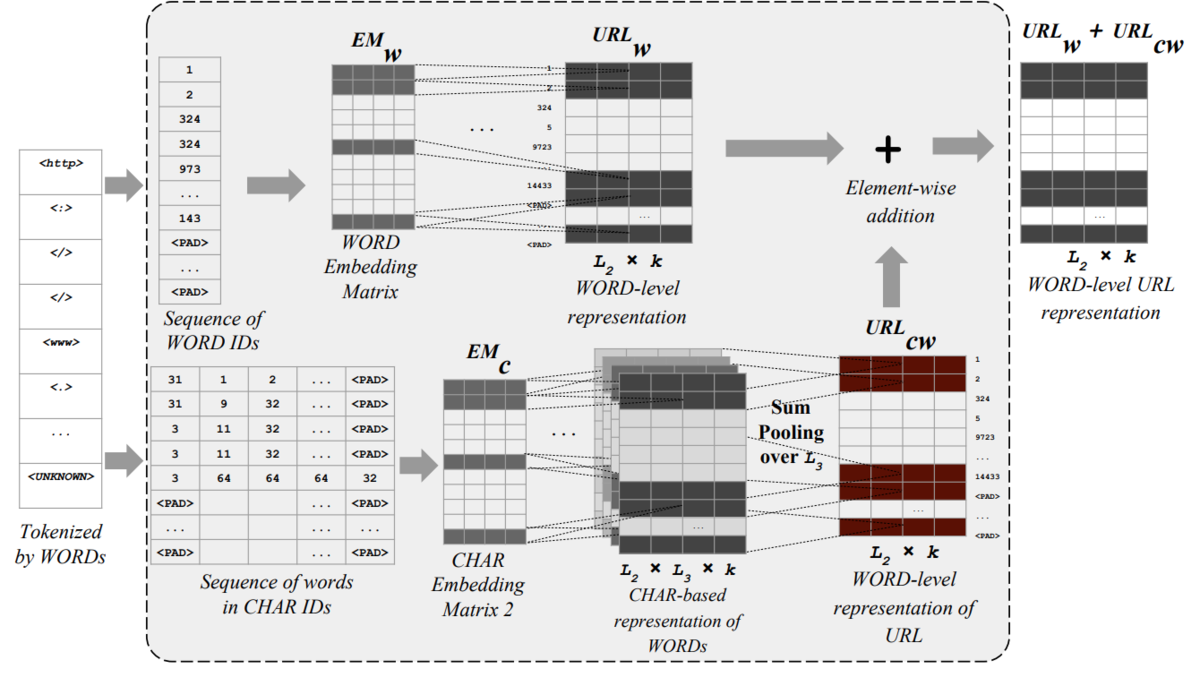
上の図をhatenaを例にみてみます。
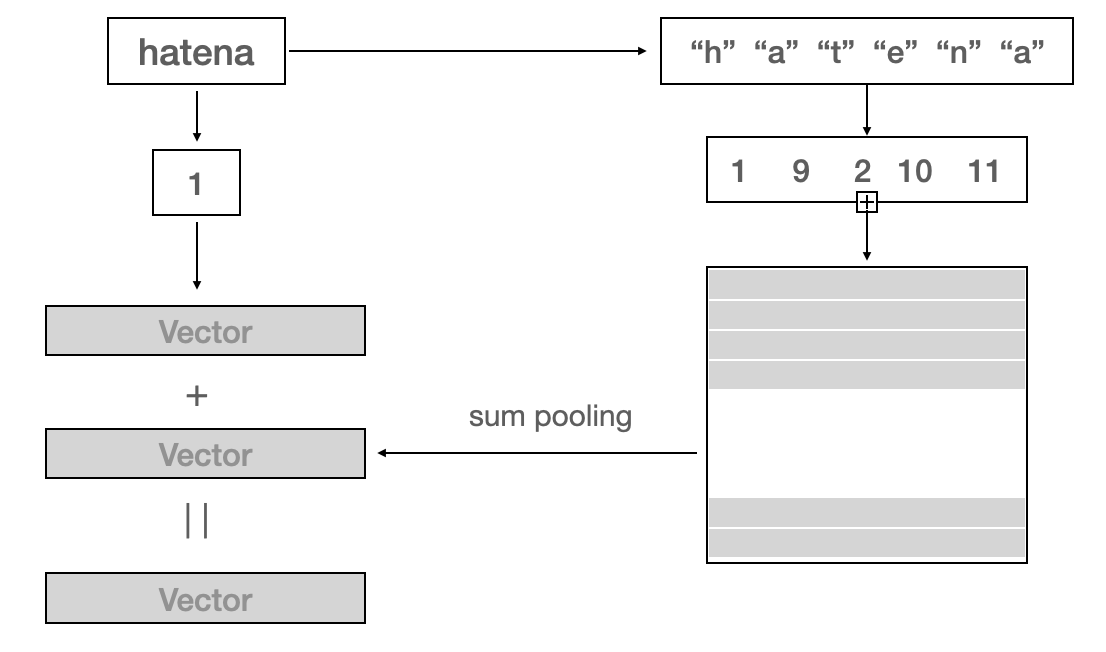
hatenaをベクトルで表現するために、Hatenaをword ID=1で指定されたベクトルと、Hatenaの各文字のベクトルを足し合わせた表現、二つのベクトルを足し合わせることによって算出されます。URLの場合だと、各単語にこのやり方が適用されるので、URLから行列の表現に変換されCNN層に入り込むことになります。
単語を文字ベースでベクトル化することによって、モデルがみたことのない単語が入力された場合でもベクトル化が可能になります。(単語ベースのベクトルはゼロとされる)
うまくまとめる事が出来ませんでしたが、次回はもう少し頑張るようにします ^^